Environment
- OS: macOS Big Sur 11.4
- CPU: Apple M1
- Compiler: Apple clang version 12.0.5 (clang-1205.0.22.11)
- Target: arm64-apple-darwin20.5.0
Problem:
struct A {
uint8_t data8;
uint64_t data64;
uint32_t data32;
};
/* What's the difference and why? */
struct B {
uint64_t data64;
uint32_t data32;
uint8_t data8;
};
Difference between these structures is in data alignment which depends mostly on your compiler configuration.
Example (and header) how to conveniently check similar structs for education purpose
(Example uses tuples to make code smaller)
Consider following code (it uses function from the link above):
printTupleInfo(std::tuple<uint8_t, uint64_t, uint32_t>());
printTupleInfo(std::tuple<uint64_t, uint32_t, uint8_t>());
The output of the code above:
[T = std::__1::tuple<unsigned char, unsigned long long, unsigned int>]
sizeof = 24
alignment_of = 8
[t = unsigned char]
sizeof = 1
value = 0
[t = unsigned long long]
sizeof = 8
value = 0
[t = unsigned int]
sizeof = 4
value = 0
[T = std::__1::tuple<unsigned long long, unsigned int, unsigned char>]
sizeof = 16
alignment_of = 8
[t = unsigned long long]
sizeof = 8
value = 0
[t = unsigned int]
sizeof = 4
value = 0
[t = unsigned char]
sizeof = 1
value = 0
Despite that structures have exactly the same amount and types of fields the sizes of the structs are different.
What’s going on?
Short answer is because CPUs are word oriented (not byte oriented).
Long answer
On the 64-bit CPU sizeof(word) will be 8 bytes and for 32-bit is 4 bytes accordingly, so accessing aligned data is simply saying more optimized (more on this here https://developer.ibm.com/technologies/systems/articles/pa-dalign/).Data in structures is aligned to the data's size
(data_address % sizeof(data) == 0)
and depending on the order there can be different amount of pads. For example `char` should be aligned to 1, `wchar` should be aligned to 2, `float` should aligned to 4 and `long long` to 8. Alignment in array is explained further.
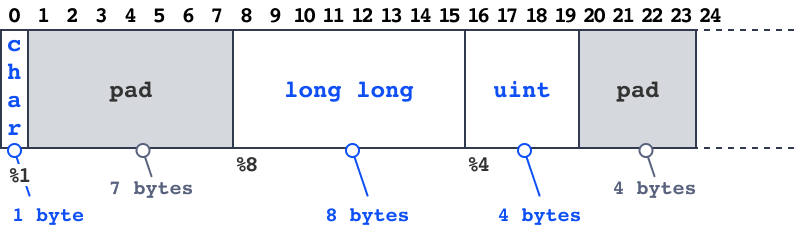
Hence long long should be aligned to a multiple of 8 we get a 7 byte pad before it. Second pad is inserted in order not to loose alignment when used in array. For example the long long field should be aligned to a multiple of 8 and without second pad second element in array won’t have a long long field aligned to a multiple of 8.

Thanks to padding long long haven’t lost its alignment.
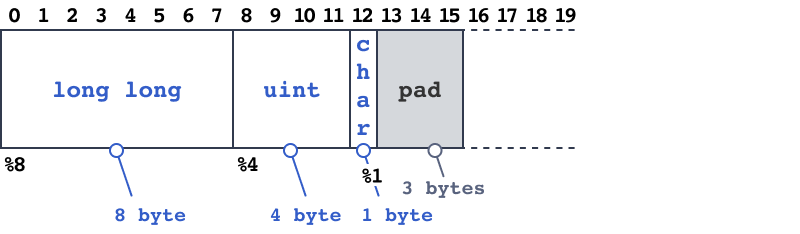 This is the same object, but due to alignment it will weight less than
This is the same object, but due to alignment it will weight less than struct A object. So different fields order will result to different memory object representation. This can lead to unobvious errors. For example to be as fast as possible you send a struct as a piece of memory over the network (ignore Endian problems 😄) and after a while occasionally (or intentionally) you change the order of fields and get corrupted values because now mapping is broken.

So in this particular case 3 objects of struct B fits to 48 bytes, while only 2 objects of struct A fits to the same 48 bytes. Quite good optimization for a large amount of objects.
As a rule of thumb place fields in decreasing order to get rid of extra padding.
You can force your compiler not to align data, but then the processor will have to perform more instructions to access not aligned fields (by combining first part from first word and second part from the second word).
P.S. If you want to get an alignment of your structure here is an example:
class Test
{
int a;
char b;
};
/* C++11 way */
std::cout << "Alignment of [T = Test] : " << std::alignment_of<Test>::value << '\n';
/* C++17 way */
std::cout << "Alignment of [T = Test] : " << std::alignment_of_v<Test> << '\n';
/* alignof way, but can't be used in templates */
std::cout << "Alignment of [T = Test] : " << alignof(test) << '\n';
TODO
- Perform perf tests on accessing aligned/unaligned data
- Checkout alignas
- Checkout std::aligned_storage
- Checkout std::aligned_alloc
- Checkout std::aligned_union
- Checkout std::max_align_t
- Checkout compiler specific align operations
- Checkout assume_aligned
- Checkout std::align
- Checkout std::launder